面向扫描型 PDF先 OCR 再检查以可读性为中心
扫描 PDF 转 EPUB
把扫描型 PDF 转成 EPUB,关键不只是格式变化,而是通过 OCR 把图像页尽量恢复成可读内容。
拖放 PDF 文件到这里
或
支持 PDF 格式,最多 30 个文件,单文件最大 200MB,1500 页以内

把扫描 PDF 转成真正可读的 EPUB
扫描 PDF 转 EPUB 的重点在于 OCR 后的可读性。用户真正要的不是一个形式上的输出,而是一份能够继续读、继续查的内容。
↘
适合正在处理具体扫描文件的人
这类搜索通常不是在比大类工具,而是在解决眼前这份扫描 PDF 到底怎么变成可读 EPUB。
✓
EPUB 不能只是重新打包后的扫描页
真正有价值的是一份比原始图像页更顺手、更适合持续阅读的输出。
⌘
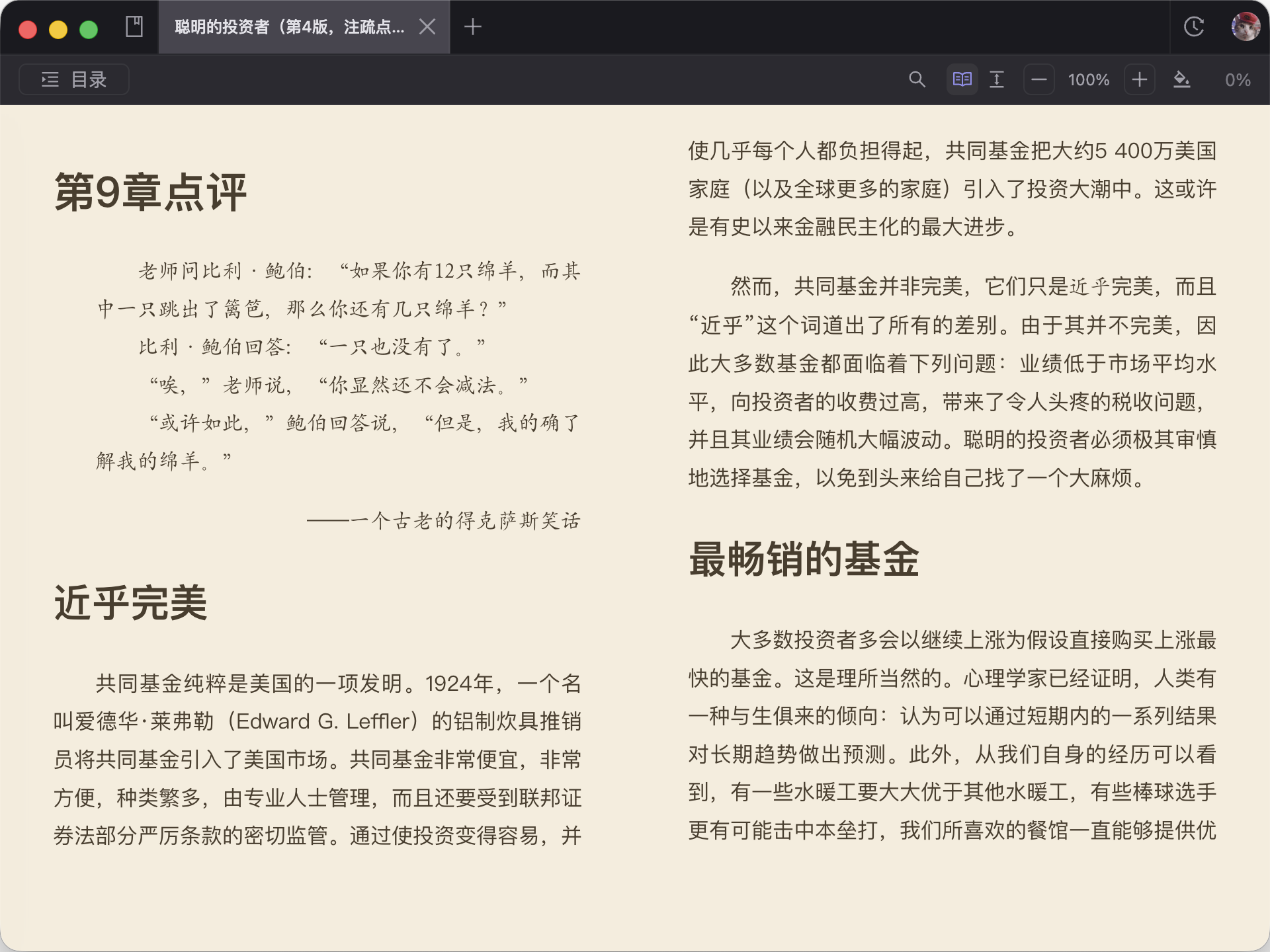
OCR 有没有达到可用水位,要靠桌面端检查
很多人会在保留文件之前,先确认文字顺不顺、顺序对不对、整体读起来是否成立。
◎
适合先核对扫描内容,再决定是否保留
下载桌面端后,可以先看识别文本是否通顺、顺序是否正确,再把这份 EPUB 放进自己的阅读或归档流程。