PDF OCR 转 EPUB
扫描版 PDF 先识别文字,再整理成 EPUB。原来不方便选中、搜索和重排的内容,也更适合继续处理。
从 PDF 格式出发,转化为 EPUB 等常用格式。接下来交给 AI 翻译、处理、分析,一个客户端统统搞定。
一类是把扫描版 PDF 做 OCR,再转成 EPUB;另一类是继续处理已有 EPUB。重点不只是换格式,而是把内容整理成后面更好读、也更好用的结果。
扫描版 PDF 先识别文字,再整理成 EPUB。原来不方便选中、搜索和重排的内容,也更适合继续处理。
已有 EPUB 不用重做,可以继续转化、整理和处理,用在不同的阅读场景和后续工作流里。
PDF 和 EPUB 都可以接上 AI 做提取、整理和转化。重点不是多一个功能,而是把内容收拾得更清楚、更可用。
OCR 任务、转化结果和最终文件都留在同一个客户端里。处理完之后,不用再换地方检查,也能直接打开继续看。
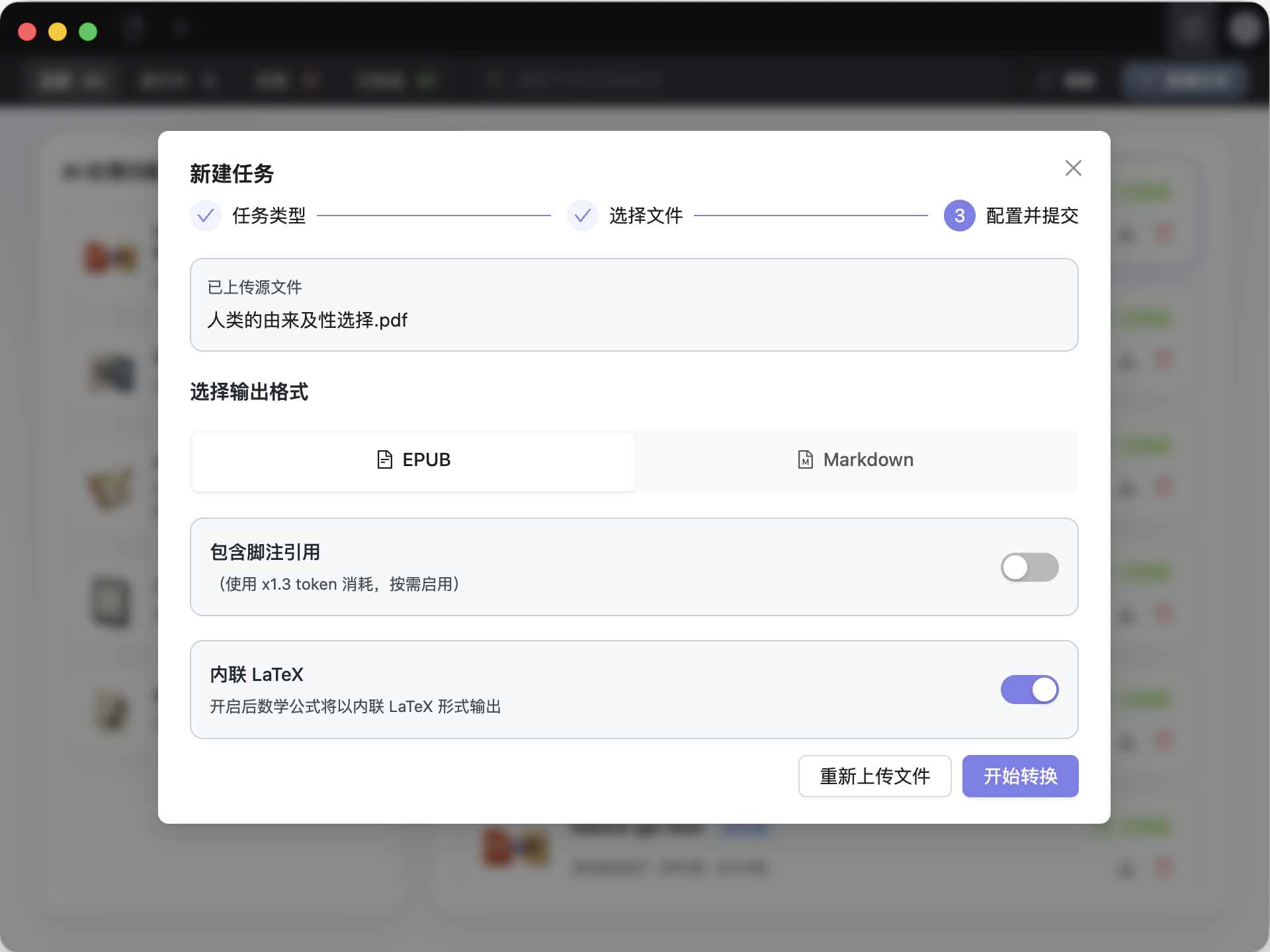
扫描版 PDF 在这里进入 OCR 流程,任务状态和处理结果都会留下来。
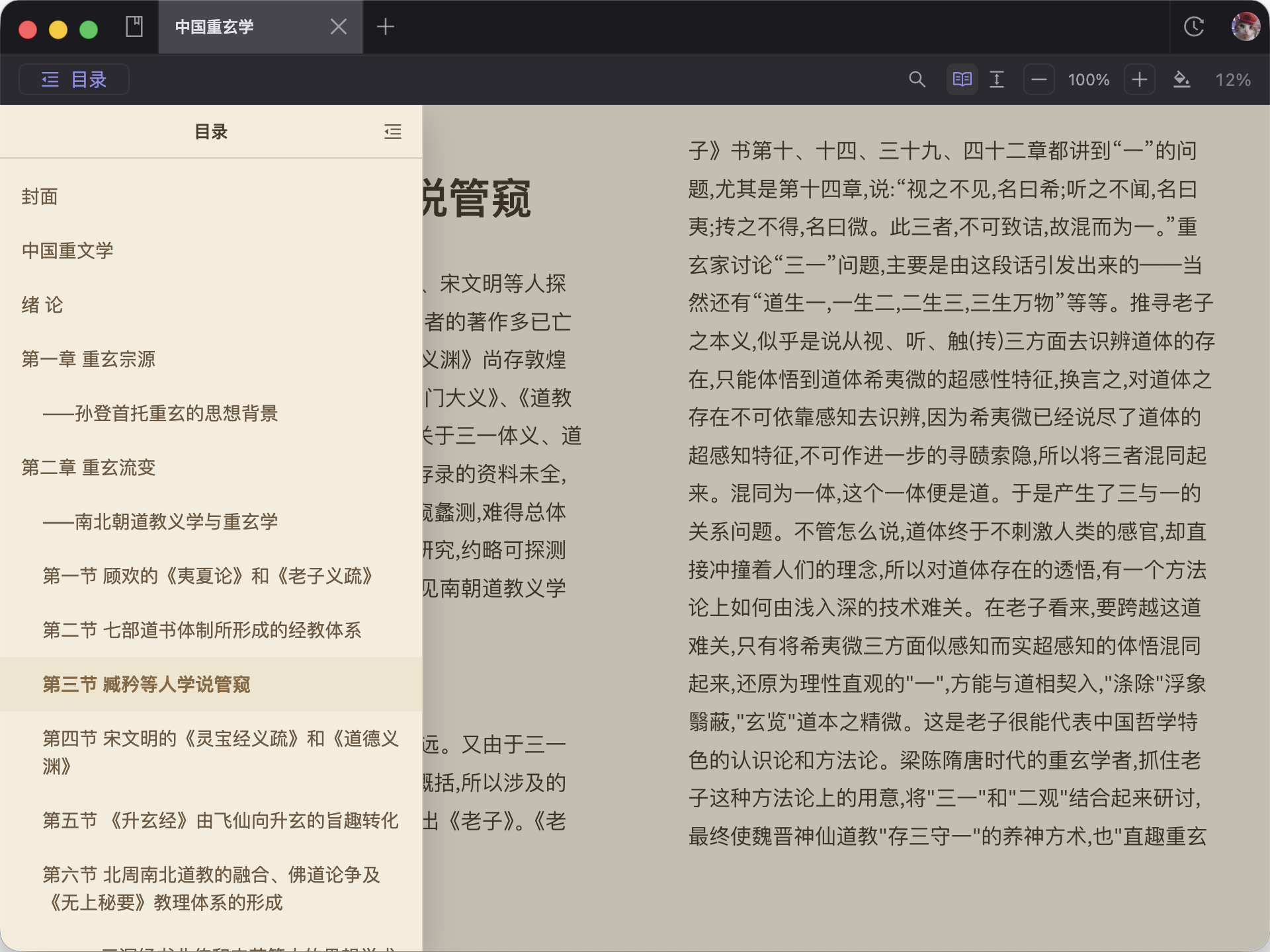
转化后的 EPUB 可以直接查看结果,也方便继续整理和再处理。

iPhone 和 iPad 上保持同样的阅读方式,拿起来就能进入内容。
适合在桌面端处理扫描版 PDF、继续整理 EPUB,并直接查看处理结果和阅读文件。
适合在 iPhone 和 iPad 上打开处理后的结果文件,用更轻便的设备继续阅读。
适合在 Apple 芯片 Mac 上处理 PDF 和 EPUB,也适合直接查看结果文件并继续整理。