面向具体文件桌面端先看结果翻完后仍是可用书本
翻译 EPUB 文件
针对一份具体 EPUB 文件做翻译,更适合用一个能看结果、能继续保留阅读副本的桌面流程来完成。
将 EPUB 文件拖拽到此处
或
直接翻译 EPUB 内容。

适合围绕具体 EPUB 文件完成翻译的场景
重点不是泛泛了解 EPUB 翻译,而是把手上的这份文件整理成还能继续阅读的版本,让章节顺序、上下文衔接和整本书的阅读结构尽量保留下来。
↘
适合已经拿到具体 EPUB 文件的人
如果目标不是了解产品类别,而是处理手上的一本书,这类页面就应该直接围绕文件本身展开。
✓
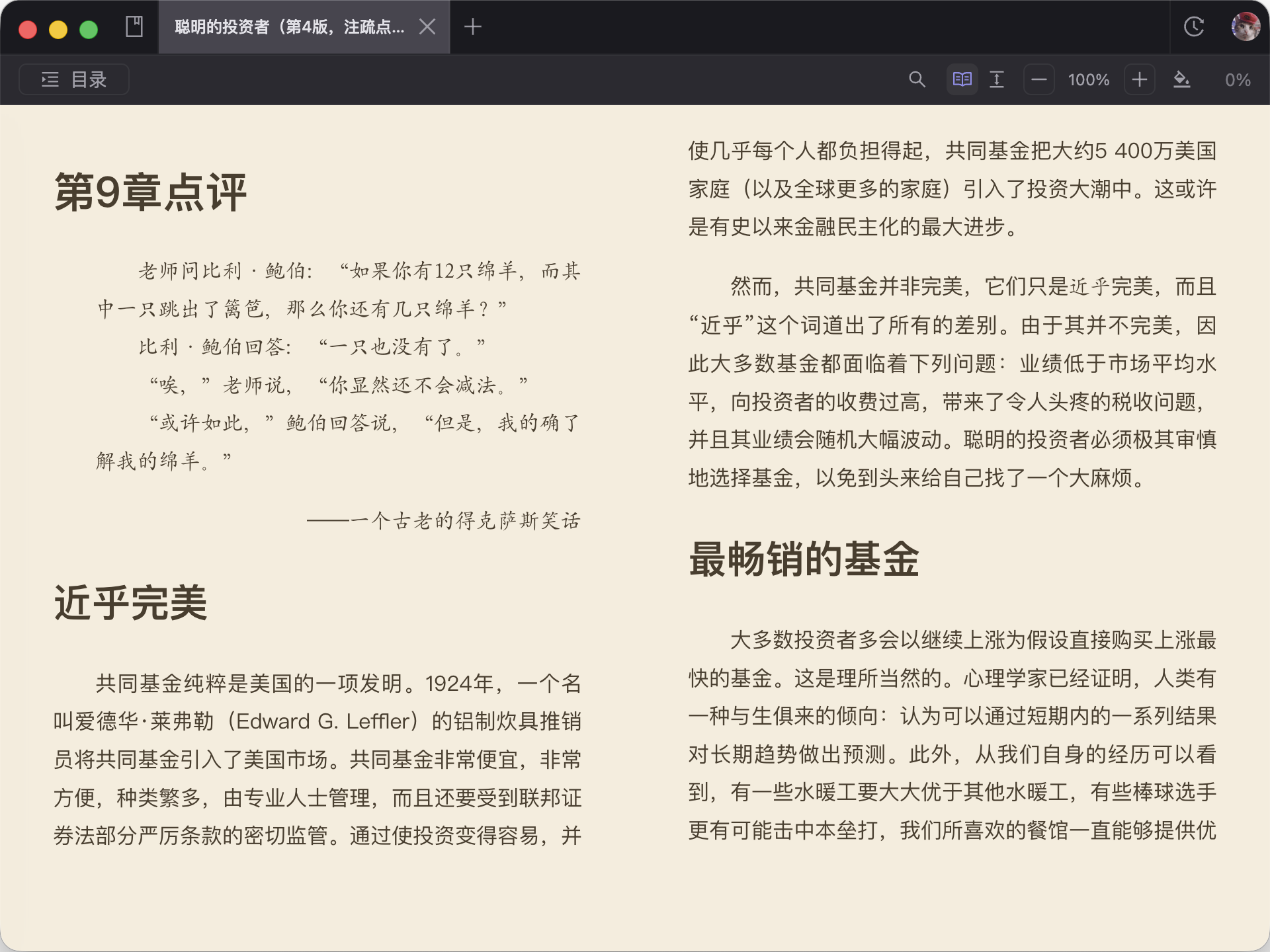
结果必须仍然像一本书,而不是一堆散翻文本
真正有价值的输出,是一份能阅读、能保存、之后还能重新打开的译后 EPUB。
⌘
文件检查本来就是翻译流程的一部分
很多人都会在保留之前先看章节、阅读流和整体观感,而不是翻完就结束。
◎
适合已经拿着具体文件准备继续处理的人
如果你已经有一份确定的 EPUB 文件,下载桌面端后先看译后章节、阅读流和整体结果,会更容易判断这份文件是否值得继续保留和阅读。